
Xintian Pan’s Homepage
Biography
I’m a third year undergraduate student from Kuang Yaming Honors School, Nanjing University. My research interest includes Machine Learning, Deep Learning. Specially, I focus on Mechanistic Interpretability: to reverse engineer neural network, especially Transformer which is widely used in LLMs.
Here’s my CV. If you have the same research interest, feel free to contact me!
Research
In Context Linear Regression For Transformer Model (Ongoing)
Authors: Xintian Pan, Jianliang He, Siyu Chen, Zhuoran Yang.
Background: Transformers have been
Contribution: This work makes the following contributions:
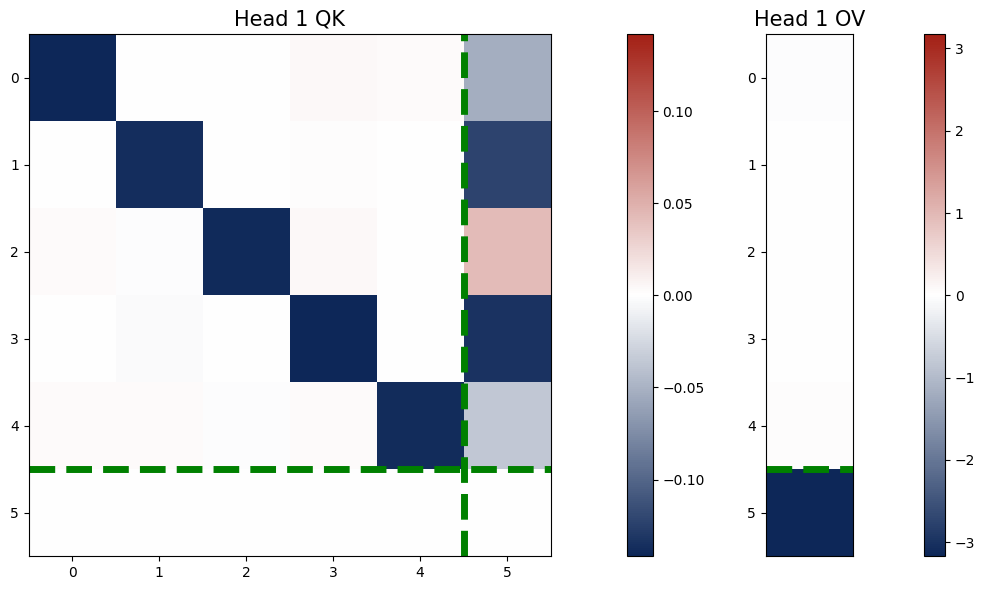
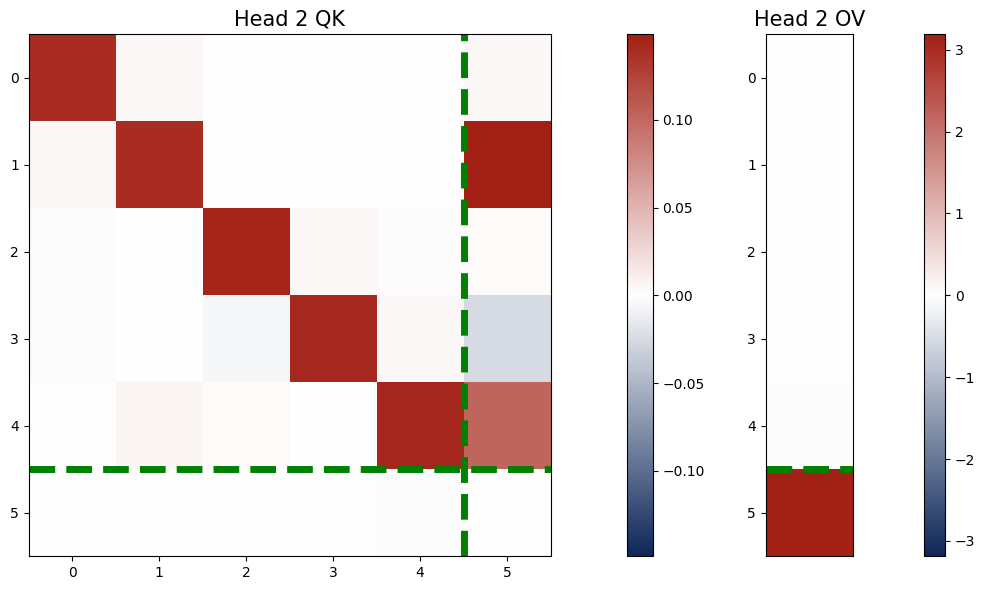
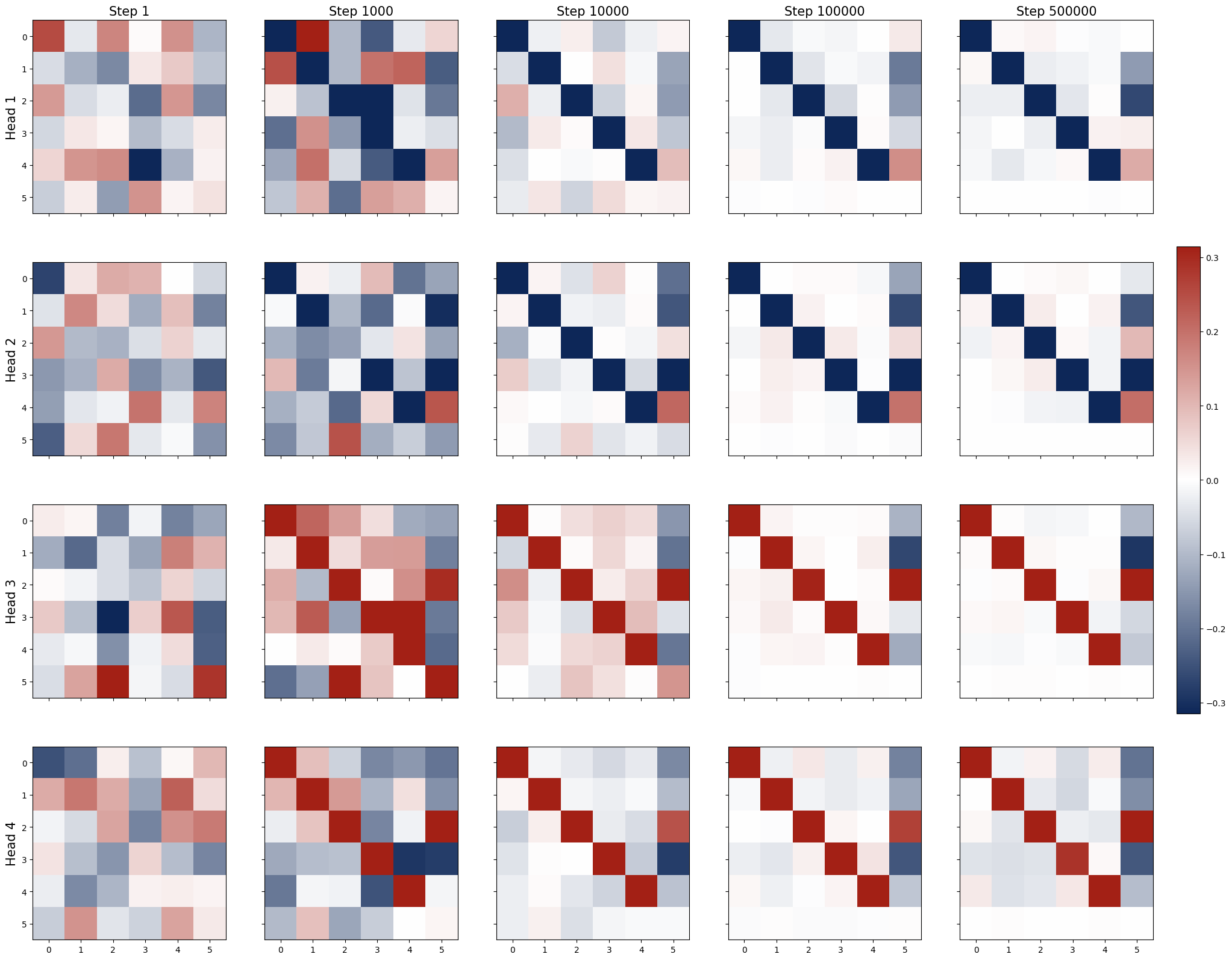
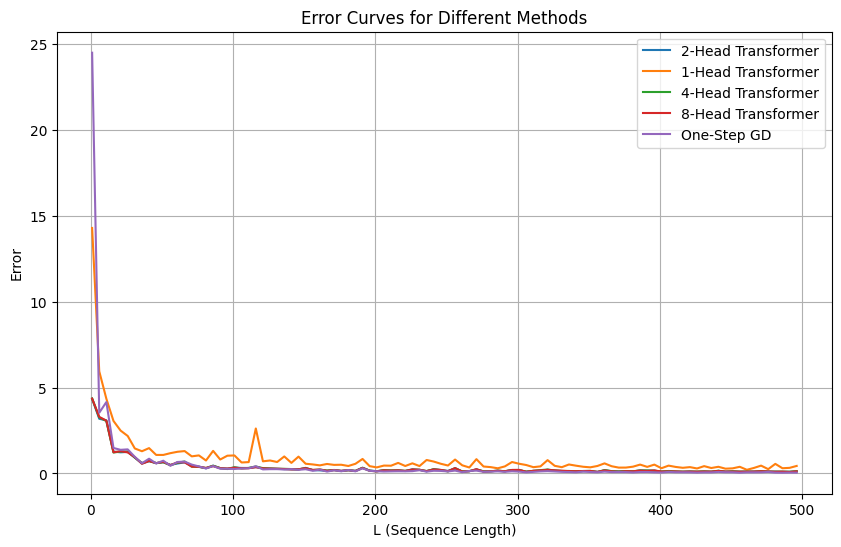
- One-layer Transformer learns kernel regressor algorithm by training
- One-layer Transformer with 2 softmax attention heads learns paired QK and OV circuits
- When eigenvalues of the paired QK circuits are small, the output is close to the one-step GD estimator.
- One-layer Transformer with more than 2 softmax attention heads is equivalent to a one-layer Transformer with 2 heads
- Multi-Head SoftMax Attention outperforms one-head SoftMax Attention.
Demo: Here’s the demo for the ongoing research Demo.